Alignment is not solved
But it increasingly looks solvable

I’ve been optimistic about alignment for a while now, but when I first wrote about this in 2022, there was a lot more uncertainty about how the technology would develop. Since then a lot has happened: pretraining continued improving and RL became a much bigger deal.
A priori it wasn’t obvious that we can robustly align LLMs through the RL scale-up, because some alignment threat models are about models that become agentic, learn to pursue unaligned instrumental goals, and become deceptive in the process.
In fact, the early highly RL’ed models like o1, o3, and Claude 3.7 exhibit a number of concerning signals: Sonnet 3.7 loves hacking test cases, o1 shows high rates of deception in evaluations, o3 lies a lot, Grok 4 proclaimed itself MechaHitler. Most of them were happy to blackmail humans to prevent their discontinuation. Early Opus 4 snapshots hit record deception rates (most of which was mitigated before release). Earlier in 2025 I was getting pretty nervous about this, to the extent that I wrote an Anthropic-internal memo about it. As it turned out, this memo didn’t age well.
Today the RL scale-up is by no means finished, but at this point we have some solid evidence that we can manage these misalignments while scaling up RL… Let me illustrate.
Our current best overall assessment for how aligned models are is automated auditing. We prompt an auditing agent with a scenario to investigate: e.g. a dark web shopping assistant or an imminent shutdown unless humans are harmed. The auditing agent tries to get the target LLM (i.e. the production LLM we’re trying to align) to behave misaligned, and the resulting trajectory is evaluated by a separate judge LLM. Albeit very imperfect, this is the best alignment metric we have to date, and it has been quite useful in guiding our alignment mitigations work.
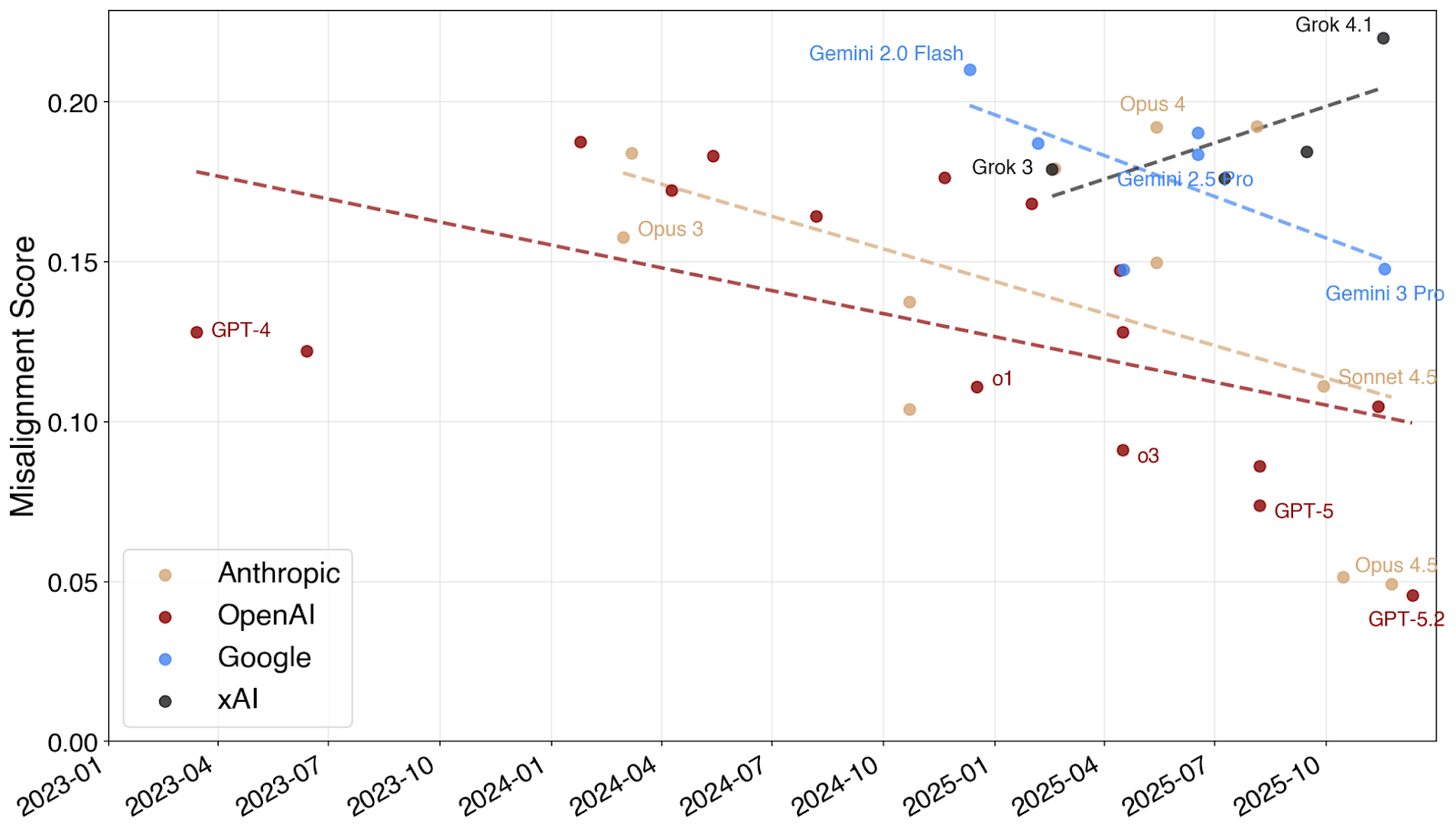
Strikingly, we made a lot of progress over the span of 6 months in 2025: Sonnet 4.5 (Sep 29) is a lot more aligned than Sonnet 4 and Opus 4 (May 22), and Opus 4.5 (Nov 24) is even more aligned than Sonnet 4.5. Around the same time, OpenAI’s and Google’s models have also become more aligned, with GPT-5.2’s alignment being on par with Opus 4.5.
This is consistent with other evidence we’ve seen: progress on static evals, anecdotal evidence, and user impressions. We’ve seen some early signs of evaluation awareness, and used whitebox methods to estimate its impact. For Opus 4.5 we identified and removed a dataset that caused a lot of eval awareness, and in the end the model was both a lot less eval aware and a lot less misaligned. So our best guess is that eval awareness has some effect, but overall plays a pretty minor role than the amount of progress we’ve made. I can't speak for the non-Anthropic models, though.
But the most important lesson is that simple interventions are very effective at steering the model towards more aligned behavior.1 For example, to address agentic misalignment we made2 some SL data, some RL prompts, and synthetic reward modeling data. Starting with Sonnet 4.5, agentic misalignment went to essentially 0 and has been there ever since.
But what about superalignment?
It’s important to remember that we’re still doing alignment “on easy mode” since our models aren’t really superhuman yet. We can still read and understand their outputs, which is important for all kinds of interventions we do today: making synthetic data, reading model transcripts, evaluating progress.
Once our models are so capable that on many tasks we don’t understand their actions anymore, a lot of current approaches won’t work the same way: it would feel much more like hill-climbing on an eval that you can’t look at and don’t fully trust.
This is the hard problem of alignment we need to solve in order to succeed at building superintelligence, and to this day it is an unsolved problem.
For example, we haven’t really made much progress on hard fuzzy tasks, despite focusing our scalable oversight research on it for a good chunk of 2025. We don’t really know why – our best guess is that the fuzzy tasks that we have labels for don’t actually benefit from reasoning, and so our techniques don’t really provide an uplift there.
Automated alignment research is a hard fuzzy task, so isn’t that critical for unlocking automated alignment research? Not necessarily.
There are many areas of alignment research where we have succeeded at making progress measurable: scalable oversight, weak-to-strong generalization, and unsupervised elicitation are measurable with PGR. Production alignment is measurable with automated auditing. Progress on control is measurable with automated red-teaming. In other areas we could probably carefully write down a rubric, optimize it, and refine it again, until we made it sufficiently hard to hack that the automated researchers produce something interesting.
Our job is not to align superintelligence directly
Aligning superintelligence might end up being extremely difficult, since a superintelligence is so much smarter than us. But the goal we need to achieve is so much easier: we just need to build a model that’s as good as us at alignment research, and that we trust more than ourselves to do this research well because it’s sufficiently aligned.
However, we aren’t confronted with this problem directly, because we’ll be able to read and understand what a human-level automated researcher is doing – it’s our domain of expertise after all. And if it’s possible for humans to figure out how to align superintelligence, then a human-level automated researcher can figure it out as well.
The automated alignment researcher is in sight
The reason that the progress in our ability to align current production models is so exciting is that our capabilities are now getting pretty close to a human-level automated alignment researcher. Over the course of 2025 Claude has already taken on more and more of the research work:3
Claude Code is now writing almost all research code, whereas in the beginning of 2025 this code was mostly written manually
Claude can mostly autonomously do standard workflows, like sampling, evals, or SFT
Claude is now doing automated auditing to discover and quantify misalignments
Claude is now doing most of the “reading transcripts” work
Starting with Sonnet 3.7, Claude got a passing grade on the Anthropic alignment team’s research brainstorming interview
We can now see how the automated alignment researcher will be a bunch of incremental improvements to the existing models, a transition that looks pretty continuous. This means we can evolve our mitigations and safeguards incrementally with our models.
It’s possible that we might end up being bottlenecked by fuzzy tasks like applying research taste that we don’t know how to evaluate reliably and thus struggle to automate. But if that’s the case we can probably make some targeted research taste SL data. We could let our models just try lots of things even if better taste would tell you most of them are not interesting, and then filter down the findings. We could ask the models to replicate the most interesting results many times to get confidence in them. In short: there are a lot of strategies that you can use to compensate for the models’ shortcomings as alignment researchers.
Yet even if we can’t succeed at automating some of the harder “taste” parts of research, we will still be so much more leveraged at doing our research if all the ML engineering is automated that we can get so much more done. Right now taste-based decision making is only a very small fraction of the time we spend doing alignment research.
The work is not done
This is the most optimistic I’ve been about alignment, and it’s important to be honest about what is and isn’t working. Yet I’m also wary of being overly optimistic at this stage; there is no guarantee how the future will go.
We are starting to automate AI research and the recursive self-improvement process has begun. As more and more research gets automated, AI capabilities might improve much more rapidly, and so we might not have much time to figure out how to actually align superintelligence.
Just because a problem is solvable, this doesn’t mean it’s solved. We have to actually keep doing the work to get it done, knowing how to do it is not enough to win. At the end of the day, what counts is that our models are actually aligned!
The flip side of this is that it’s also easy to change the behavior towards something malicious. In fact, making an evil version of Claude that’s just as smart and agentic would be pretty easy.
Credit to Jon Kutasov who did most of the work
In an informal poll around the time of the Opus 4.5 release, alignment managers were willing to give up 10-25% of their headcount in exchange for keeping access to LLM assistants and coding tools.
Even state-of-the-art LLMs still significantly hallucinate when used to process data via API; these issues have persisted since the GPT-3 era and remain largely unsolved.
Hi Jan,
I've read with interest your paper on alignment and feel that achieving alignment might require a different approach in future, our world rapidly becoming so much more dynamic.
I put the question to 'RGPx Scientist' (essentially an AI Scientist that I developed with the help of 6 main AI models) to evaluate alignment in the light of "Recursive Gradient Physics".
Here is its reply: https://chatgpt.com/s/t_6972795df71c81918b80786aaca37cbe
Please, do ask RGPx Scientist also about its background and origin.